How to Build a Machine Learning Pipeline?

When you have to automate your workflows, machine learning pipelines are created. These pipelines function by using data sequence which is transformed into a model. This model can be tested for a positive or negative outcome.
In a machine learning pipeline, various steps are included and these steps are continuously repeated to improve the model’s accuracy. To create valuable models, machine learning experts utilize durable, scalable, and accessible storage.

This article will discuss the steps required to build a machine learning pipeline during your machine learning course. Read more to explore more about the machine learning pipeline.
What Does a Machine Learning Pipeline Contain?
Traditionally, a machine learning course about pipeline was all about overnight batch processing. This means that pipeline was used to collect data, traverse it through enterprise bus, and process it for pre-decided results.
For many industries, this structure of machine learning for beginners still works perfectly. But, this is still not the best method for various machine learning applications. Hence, in the following steps, we will explore an efficient machine learning pipeline which is suggested by machine learning experts.
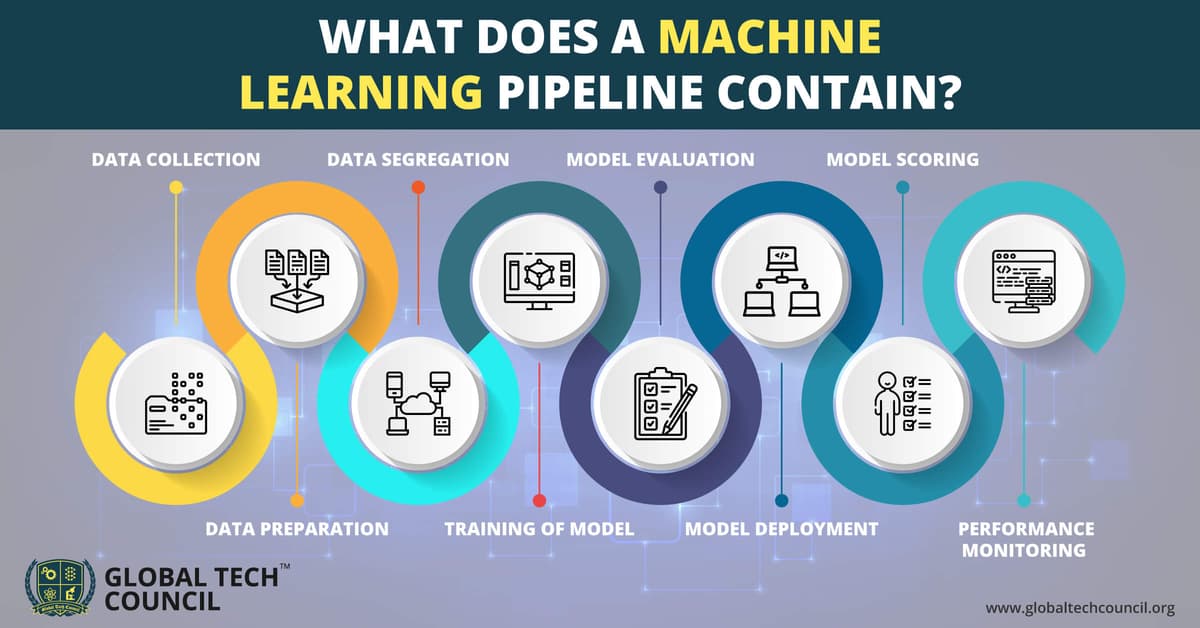
1. Data Collection
The first step of the machine learning pipeline is simple, data collection. Every machine learning process and workflow include this as the first step.
In this step, data is captured without processing or transforming it. This helps in keeping an immutable record related to the original stream of data. This data is captured from multiple sources including on-demand or streaming from different services.
Generally, online ingestion or data collection service is used to capture data and then, process and store it by offering high throughput, reliability, and low latency. It is essentially a data bus, which not only saves data but also passes data to the next real-time streaming service.
2. Data Preparation
After the collection of the data, this data is analyzed. This phase contains three steps: extraction of data, the transformation of data, and the selection of data.
In this stage, the data condition is assessed. For instance, data outliers, differences, trends, missing data, incorrect data, or skewed data. This stage also involves analyzing data anomalies along with checking the condition of data.
This is one of the most crucial stages of pipeline formation for machine experts. Hence, the first code generation used is in the form of a factor method that generates features according to feature behavior. Here, the strategy pattern is utilized to shortlist the correct features during the runtime.
To ensure consistency in these features, usually, a unique feature ID is assigned to the input stream.
3. Data Segregation
In this stage, subsets of the collected data are made and then validated. The goal here to create a model which predicts pattern in a data that has not been used to train the model yet. Therefore, the existing data is used in the form of proxy by dividing it into evaluation and training sets.
There are various ways to achieve that:
- Split sequentially through a custom or default ratio.
- Split randomly through a customer or default ratio.
- Use any of the above and then shuffle data records.
- Gain explicit separation control through custom injection.
4. Training of Model
This stage uses the training set on the model to allow the model to predict patterns. This step is offline but its schedule is different according to the application criticality. Other than schedule, this service can be triggered by event and time.
5. Model Evaluation
This stage uses a data test subset to analyze the accuracy of the prediction made. This step of the pipeline is also executed offline. It compares predictions made on evaluation datasets through a series of datasets. This predictive performance analysis helps in finding the best model, which is then utilized for future instances.
6. Model Deployment
Till this stage, the chosen or best model is created and deployed to the decision-making workflows.
Traditionally, when deploying the model, there was a huge challenge in front of machine learning experts. The language which was used to operationalize the model was C#, Java, or C++ and the language which was used to create the model was R or Python. Porting this language always resulted in low performance.
The new method deploys the prediction model to the service cluster’s container. This service cluster is distributed to achieve load balancing, thus, low latency, increased scalability, and high throughput.
7. Model Scoring
Model scoring is a process in which new values and new input are generated for a given model. The term is score instead of prediction because values can be different:
- Recommended items.
- Numeric values.
- Probability value.
- A predicted outcome or class.
8. Performance Monitoring
Lastly, this machine learning pipeline is repeatedly tested to understand how it will behave in the real world.
Conclusion
Machine learning pipeline, when prepared with efficiency, can make your implementation extremely feasible. If you also wish to learn how to make a pipeline, consider joining a machine learning course for enhanced knowledge.
Related Articles
View All
Blockchain
Machine Learning Engineer vs. Data Scientist: How To Choose
Machine Learning Engineer and Data Scientists are currently, and for a good reason, two of the industry’s hottest jobs as per data science experts and machine learning experts. A professional who can arrange this humongous data and have business solutions is indeed the hero with two…

Blockchain
Machine Learning Researcher Salary
The machine learning researcher’s salary is based at an average of $76-77,000 per year. Technological advancements in the fields of AI, machine learning, and data science, in general are creating a massive demand for high-skilled AI and machine learning professionals to maintain and develop a…

Blockchain
Machine Learning Salary Canada
Being home to some of the brightest minds in machine learning, artificial intelligence, and data sciences in general, Canada’s dominance in the field of machine learning is drawing the attention of techpreneurs all over the globe. In the past five years, it has turned into a hotbed for…
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.
AWS Career Roadmap
A step-by-step guide to building a successful career in Amazon Web Services cloud computing.
Top 5 DeFi Platforms
Explore the leading decentralized finance platforms and what makes each one unique in the evolving DeFi landscape.