Use of Distributed Hash Tables (DHTs) & Merkle DAGs in IPFS Content Addressing
IPFS, even among many in the Valley, is not exactly a well-known technology yet, but it is spreading quickly by word of mouth among people in the open-source community. Many are thrilled by its ability to boost file transfer and streaming speeds across the Internet significantly. In a way that is related to how the web connects all these websites, IPFS connects all different blockchains. IPFS is a future technology that would help the Internet grow into the system we’ve always aspired to be. This article discusses how Distributed Hash Tables (DHTs) & Merkle DAGs are used in IPFS Content Addressing.

Table of Contents
- What is IPFS?
- How does IPFS work?
- Distributed Hash Tables (DHTs)
- How to use DHTs?
- Merkle DAGs in IPFS Content Addressing
- Conclusion
Are you interested in learning more about Distributed Hash Tables (DHTs) and Merkle DAGs? You can learn more about how DAGs and DHTs are used to create intelligent machine learning solutions in our courses on chatbot and machine learning.
What is IPFS?
IPFS stands for Interplanetary File System. IPFS is a distributed system for files, websites, applications, and data storage and access. It also describes how files move across a network, making it, much like BitTorrent, a distributed file system. IPFS enables a new permanent web by combining these two properties and increases the way we use existing internet protocols such as HTTP.
How does IPFS work?
IPFS seeks to create a web that is both permanent and distributed. Using a content-addressed system instead of the location-based system of HTTP does this. IPFS utilizes a representation of the content itself to address the content instead of using a location address. A cryptographic hash on a file is used to do this, which is used as the address. The hash represents a root object, and in its path, you can find other objects.
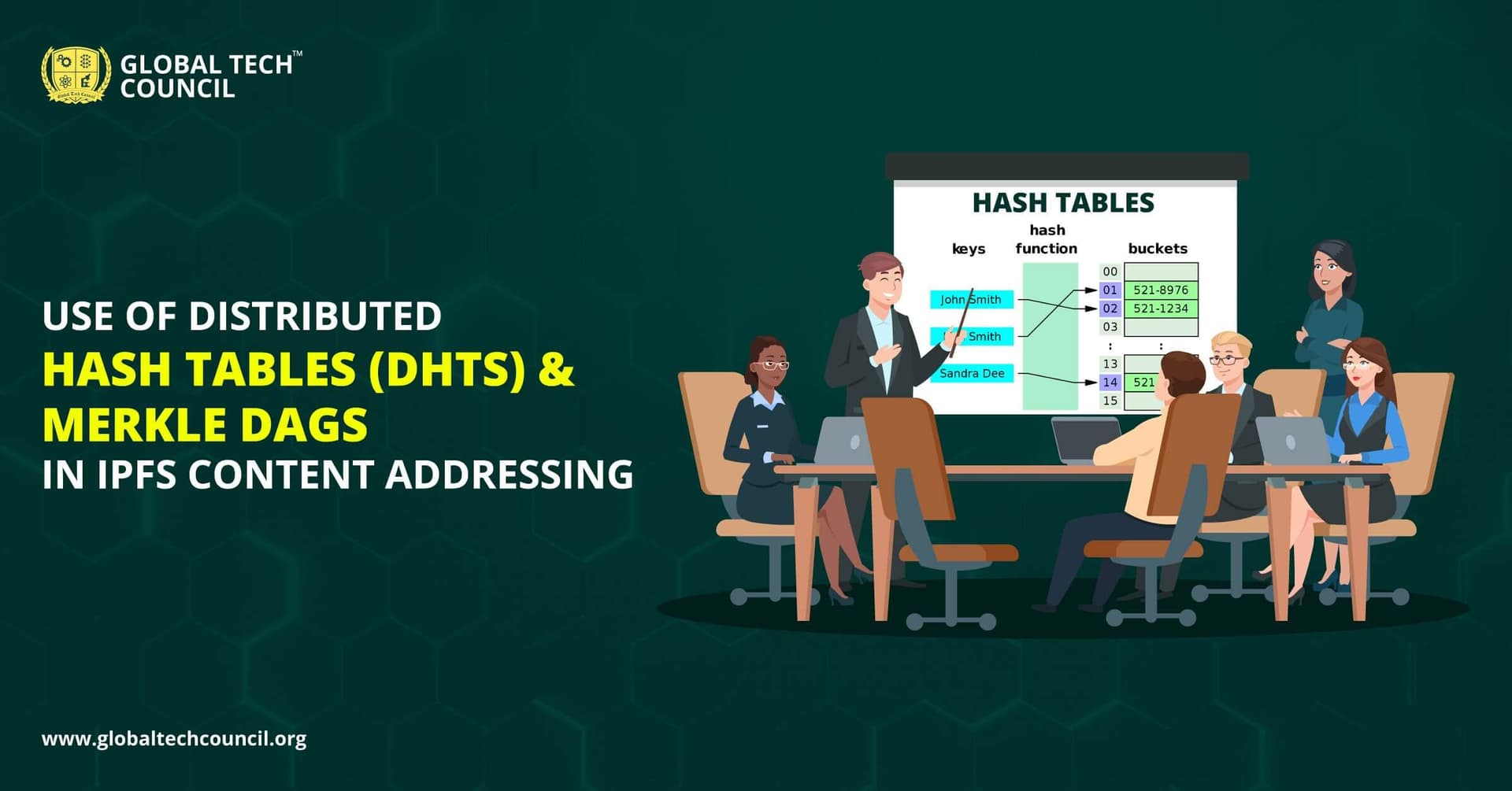
Distributed Hash Tables (DHTs)
A distributed hash table (DHT) is a distributed system designed to map values to keys. The DHT is used in IPFS as the fundamental component of the routing system for content and acts as a cross between a catalog and a navigation system. It maps to the peer who is storing the matching content that the user is looking for. Think of it as an enormous table storing data.
IPFS and other decentralized content systems use something called a distributed hash table (DHT) to support routing and the discovery of content and peers on the network. So when you hear someone say something like: “request the network,” “ask the network,” or “get it from the network,” what they’re saying is “request the distributed hash table.” Without any centralized coordination, this enables peers on the network to find content or peers.
How to use DHTs?
When a node gets a search request, it returns the corresponding value if it is in its own bucket; otherwise, the connection information (IP + port, peerID, etc.) of the closer node will be returned. The requesting node is then capable of sending its request to the nearer node. This process goes on until a certain node can answer.
At most log2 (n) steps, or even log2 m (n) steps, a hash request of length n requires.
Merkle DAGs in IPFS Content Addressing
A Merkle DAG is a DAG where each node has an identifier. This results from hashing the contents of the node, using a cryptographic hash function such as SHA256 opaque payload carried by the node and its children’s list of identifiers. This brings with it some significant considerations:
- Only from the leaves, that is, from nodes without children, can Merkle DAGs be constructed. After children, parents are added because the children’s identifiers must be computed in advance to be able to link them.
- Every node in a Merkle DAG is the root of the (sub)Merkle DAG itself, and the parent DAG contains this subgraph.
- There are immutable Merkle DAG nodes. Any change in a node would change its identifier and affect all the ascendants in the DAG, creating a different DAG in essence. Please take a look at this helpful illustration from our friends at Consensys using bananas.
Merkle DAGs are similar to Merkle trees, but there are no equilibrium specifications, and every node can carry a payload. Multiple branches may re-converge in DAGs or, in other words, a node may have several parents. It is referred to as content addressing to identify a data object (like a Merkle DAG node) by its hash value. Therefore, as a Content Identifier, or CID, we name the node identifier.
Merkle DAGs are self-verified structures. A node’s CID is unambiguously linked to its payload content and to that of all of its descendants. Thus, two nodes univocally represent precisely the same DAG with the same CID. This will be a crucial feature for synchronizing Merkle-CRDTs effectively without copying the full DAG, as exploited by systems such as IPFS. DAGs from Merkle are widely used. To effectively store the repository history, source control systems such as git and others use them in a way that enables objects to be de-duplicated and conflicts between branches to be detected.
Conclusion
By nature, IPFS and other projects from Protocol Labs are ambitious. No doubt, the goals of the original inventors of our internet protocols were also the idea of a permanent web that is resilient and efficient. Over time, however, as our web usage changed, weaknesses in these protocols became apparent. Although IPFS is in its initial stages, it shows promise to be a vital piece of a new decentralized stack of technology.
Related Articles
View All
Machine Learning
How does Spotify use machine learning to analyze data and make decisions?
Spotify, the largest on-demand music agency within the entire world, embraced documents of compelling bounds from the scientific state using the latest technologies to market victory. Spotify today has millions of online subscribers. The reason for its success lies in Spotify’s innovative use…

Machine Learning
Machine & Deep Learning in Mobile Video Game AI Development
Someone once thought about what if computers were able to learn independently and progress without any human programming or help from experience using data. This theory came to be known as Machine Learning, and the name behind was Arthur Samuel. Thanks to the substantial volume of data available…

Machine Learning
Top 5 Google Products that Use ML Behind the Scenes
”Machine learning is a core, transformative way by which we’re rethinking how we’re doing everything. We are thoughtfully applying it across all our products: search, ads, YouTube, or Play. And we’re in early days, but you will see us –in a systematic way — apply machine learning in all these…
Trending Articles
The Role of Blockchain in Ethical AI Development
How blockchain technology is being used to promote transparency and accountability in artificial intelligence systems.
AWS Career Roadmap
A step-by-step guide to building a successful career in Amazon Web Services cloud computing.
Top 5 DeFi Platforms
Explore the leading decentralized finance platforms and what makes each one unique in the evolving DeFi landscape.