 What is Model Quantization Techniques
What is Model Quantization Techniques
 What is Model Quantization Techniques
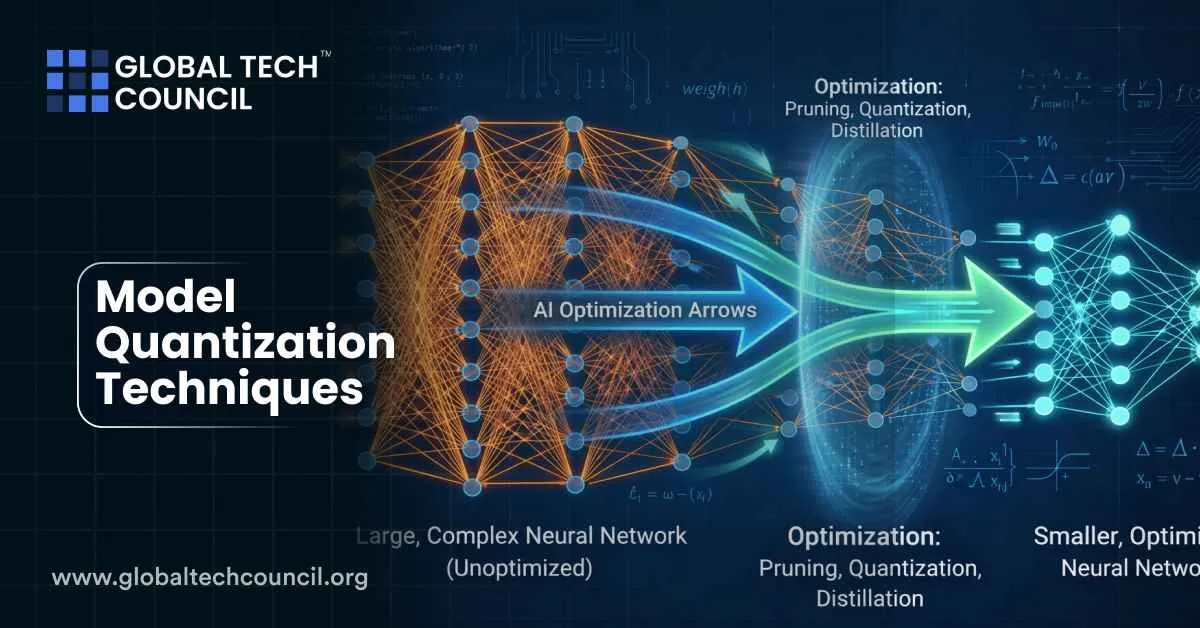
What is Model Quantization TechniquesModel quantization technique is a machine learning optimization technique that reduces the precision of numbers used to represent neural network parameters and computations. Instead of using high-precision values such as 32-bit floating-point numbers, quantized models use lower-precision formats like 16-bit or 8-bit integers. This significantly reduces memory usage and computational requirements while maintaining acceptable accuracy.
As artificial Intelligence systems grow larger and more complex, deploying them efficiently becomes challenging. Quantization helps make these models smaller, faster, and more energy-efficient, enabling them to run on smartphones, edge devices, and other resource-limited environments.
Because of its importance in real-world AI systems, model quantization is increasingly studied by engineers and developers pursuing a Tech certification focused on modern computing technologies.
Why Quantization Matters in AI
Modern neural networks often contain millions or even billions of parameters. Running such models requires substantial computational power and memory resources.
Quantization addresses these challenges by compressing models and simplifying mathematical operations. Lower-precision values reduce data movement and memory bandwidth usage, improving performance and power efficiency.
Key benefits include:
- Faster inference speed
- Reduced memory usage
- Lower energy consumption
- Easier deployment on edge devices
These advantages make quantization especially valuable in industries that require real-time predictions or operate on constrained hardware.
How Model Quantization Works
Quantization converts high-precision values into lower-precision representations. In deep learning models, this process typically affects weights, activations, and sometimes gradients.
The main goal is to maintain model accuracy while improving efficiency. However, reducing precision can introduce rounding errors or small losses in predictive performance.
Developers therefore apply specialized techniques to balance efficiency and accuracy.
Major Quantization Techniques
Several quantization approaches are widely used in modern machine learning systems.
Post-Training Quantization
Post-training quantization (PTQ) converts a trained model into a lower-precision version after training is complete. This method is simple and efficient because it does not require retraining the model.
It is commonly used when developers want to deploy models quickly on edge devices or mobile applications.
However, PTQ may cause a small reduction in accuracy, especially in complex models.
Quantization-Aware Training
Quantization-aware training (QAT) incorporates quantization into the training process itself. During training, the model simulates lower-precision operations so it can adapt to them.
Because the model learns to handle reduced precision, QAT often produces better accuracy compared with post-training methods.
This technique is widely used for deploying high-performance AI models in production systems.
Dynamic Quantization
Dynamic quantization adjusts precision during inference. Instead of quantizing the entire model beforehand, the system converts values to lower precision dynamically while performing calculations.
This method is useful for models used in natural language processing and large language models.
Static Quantization
Static quantization pre-computes scaling factors and converts model weights and activations before inference. It typically provides better runtime performance but requires calibration using sample data.
Many frameworks such as TensorFlow and PyTorch support this approach.
Quantization in Large Language Models
Large language models (LLMs) are among the most computationally demanding AI systems. Quantization has become a key method for making these models deployable on practical hardware.
By reducing precision, quantization significantly decreases memory usage and computational cost without dramatically affecting performance.
Some recent research has even demonstrated that models using 8-bit or lower precision can maintain strong accuracy while running faster on edge devices.
This progress is making advanced AI systems more accessible to businesses and developers.
Real-World Applications
Quantization is widely used across many industries.
Mobile AI Applications
Smartphone assistants, translation apps, and recommendation systems rely on optimized models that can run efficiently on limited hardware.
Autonomous Systems
Self-driving vehicles and robotics platforms require real-time decision making. Quantized models help reduce latency while maintaining accuracy.
Healthcare Technology
Medical imaging tools use quantized neural networks to analyze scans quickly while minimizing hardware requirements.
Edge Computing
Internet of Things devices depend heavily on lightweight models that can operate without powerful cloud infrastructure.
These examples demonstrate how quantization enables AI deployment in practical environments.
Benefits of Model Quantization
Quantization offers several major advantages for machine learning systems.
Reduced Model Size
Lower-precision numbers require less storage space, enabling models to fit into smaller devices.
Faster Computation
Integer arithmetic operations are faster than floating-point operations.
Lower Power Consumption
Efficient models require less energy, which is important for battery-powered devices.
Cost Efficiency
Organizations can run AI models on less expensive hardware infrastructure.
These benefits make quantization a critical tool in modern AI development.
Challenges and Limitations
Despite its advantages, model quantization also presents several challenges.
Accuracy Loss
Reducing precision may introduce errors that affect predictions.
Hardware Compatibility
Different hardware accelerators support different quantization formats.
Implementation Complexity
Choosing the right quantization strategy requires experimentation and technical expertise.
Researchers continue developing methods to overcome these limitations and improve model performance.
Education and Skills in AI Optimization
As machine learning systems become more sophisticated, professionals need strong knowledge of optimization techniques such as quantization.
A Tech certification can help individuals build foundational skills in emerging technologies, including AI infrastructure and model optimization.
Similarly, developers working directly with machine learning models often pursue an AI certification to deepen their understanding of advanced AI systems and deployment strategies.
For professionals applying AI insights to business strategy and customer engagement, a Deep Tech Certification and marketing certification can help connect technical innovation with market impact.
These educational pathways support the growing demand for AI expertise across industries.
Recent Developments in Quantization Research
Recent advancements in quantization focus on improving efficiency while maintaining accuracy.
Researchers are exploring adaptive quantization methods that dynamically adjust precision based on model behavior. Other studies investigate new optimization strategies that improve post-training quantization performance.
Innovations such as re-quantization frameworks allow models to be adapted for different hardware environments without retraining from scratch.
These developments continue expanding the practical use of AI models across devices and industries.
The Future of Model Quantization
As artificial Intelligence continues evolving, quantization will play an increasingly important role in making models scalable and accessible.
Future AI systems will likely combine quantization with other optimization techniques such as pruning, distillation, and hardware acceleration. Together, these technologies will enable powerful models to run efficiently on everyday devices.
Organizations that adopt these techniques will be better positioned to deploy AI at scale.
Conclusion
Model quantization techniques are essential for modern AI deployment. By reducing the precision of neural network parameters and computations, developers can dramatically improve performance, reduce costs, and enable models to run on resource-constrained hardware.
From smartphones and autonomous vehicles to healthcare diagnostics and cloud services, quantization is helping bring advanced artificial intelligence into real-world applications. As research continues and tools improve, quantization will remain a cornerstone of efficient machine learning systems.